A search indexer, often referred to simply as an indexer, is a core component of search engines and information retrieval systems. It is the software responsible for processing collected content (usually web pages) and storing it in a structured, optimized database called an index. This index enables the incredibly fast search results we experience.
What is a Search Indexer?
Think of a giant library. The indexer's job is analogous to creating the library's detailed catalog:
- Raw Materials: The crawler gathers web pages (documents).
- Processing: The indexer analyzes each page.
- Catalog Creation: It builds a massive database (the index) mapping words, phrases, and specific data points to the documents they appear in, storing additional information like location and frequency.
The resulting index is not a mirror of the web; it's a highly optimized data structure designed for one primary purpose: speed up finding relevant documents for user queries.
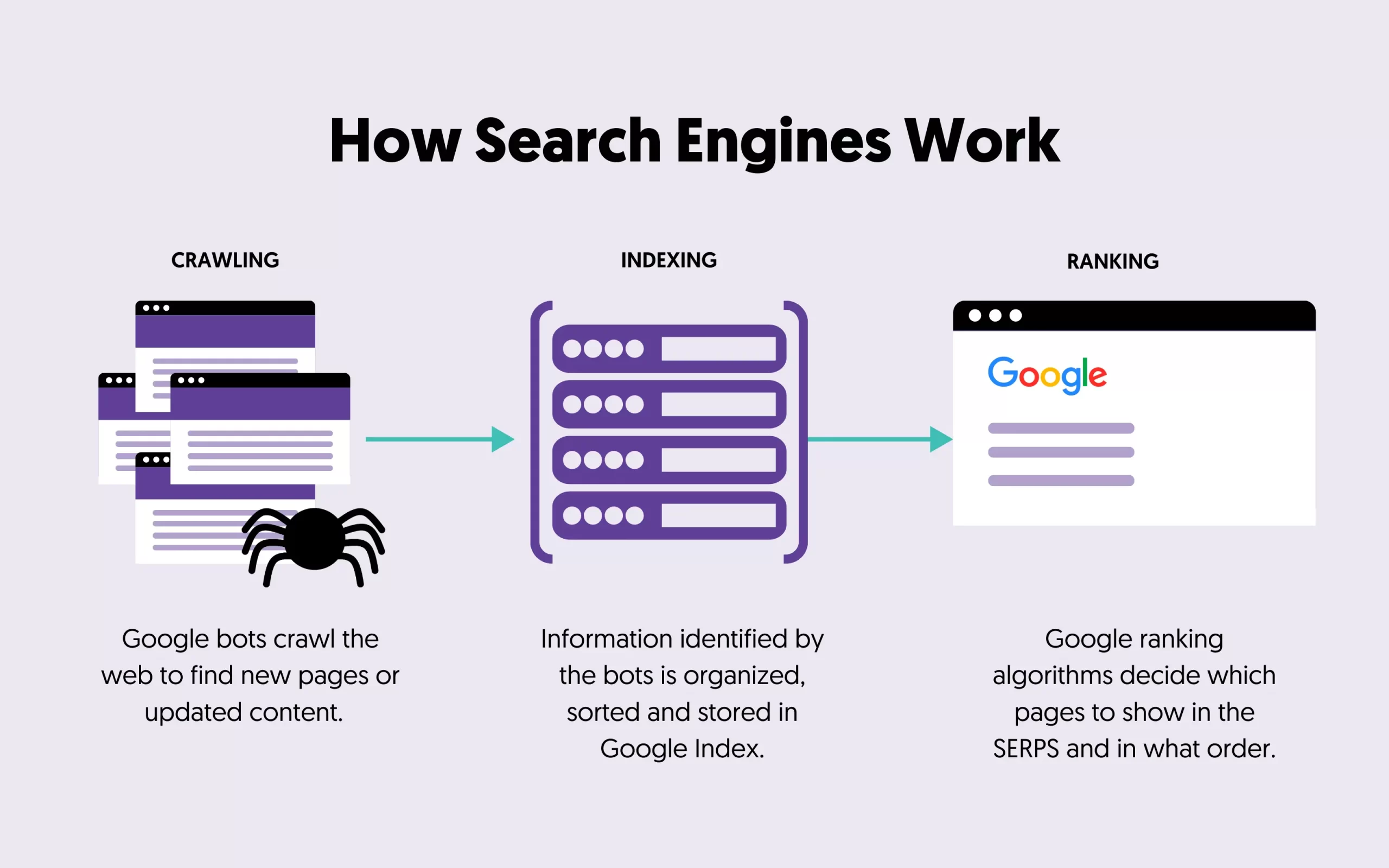
How a Search Indexer Works
The indexing process generally follows these key steps:
-
Content Acquisition:
The indexer receives the raw content (HTML code, text, metadata) discovered by the crawler.
-
Parsing and Text Extraction:

The software parses the HTML, identifying key elements like titles, headings, paragraphs, and links. Crucially, it extracts the visible text content that users see on the page, often ignoring code, scripts, and certain formatting.
-
Processing and Analysis:
The extracted text undergoes significant processing:
- Tokenization: Breaking the text stream into individual words, symbols, or meaningful sequences (tokens).
- Normalization: Converting tokens to a standard format (e.g., lowercasing, removing accents).
- Stemming/Lemmatization: Often reducing words to their root form (e.g., "running", "runs" -> "run").
- Stop Word Removal: Filtering out extremely common words (e.g., "the", "is", "and") that carry little search meaning.
-
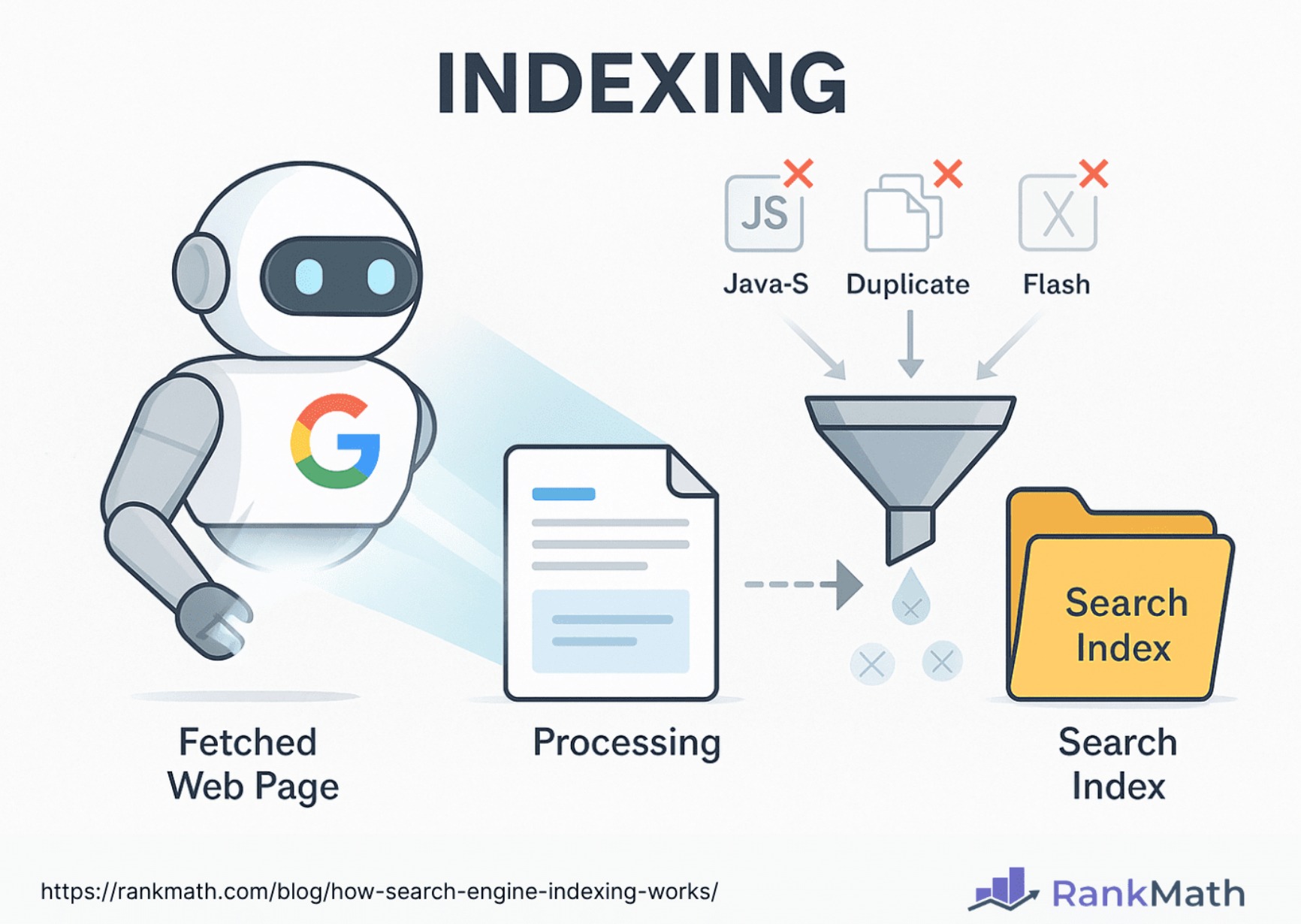
Building the Index:
This is the core function:
- For each significant token (word, phrase, entity) identified, the indexer creates an entry in the index database.
- Each entry maps the token to a list of documents (and specific locations within those documents) where it appears.
- It stores additional information like the frequency of the token in each document, its position, prominence (e.g., in headings vs. body text), document metadata (like titles), and possibly link analysis data.
-
Storing the Index:
The processed data is saved onto disk in specialized, highly compressed data structures optimized for fast read access across massive servers.
-
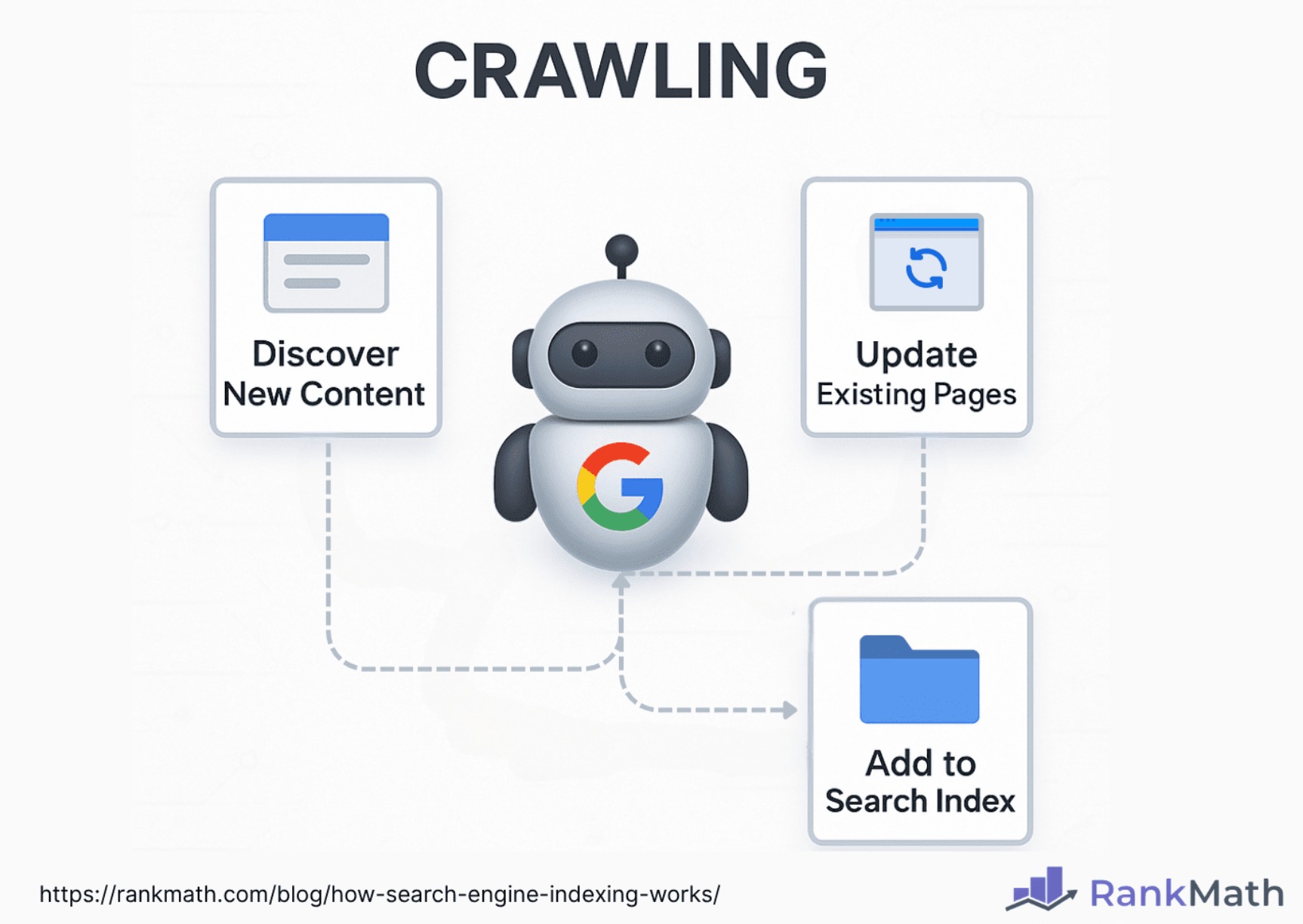
Updating the Index:
Indexes are not static. As the crawler discovers new pages or updated versions of existing pages, the indexer continuously processes them and updates the index entries accordingly (adding new references, adjusting frequencies, removing references to deleted content).

The End Goal: Enabling Instant Search
The indexer's meticulous work creates the database that allows the query processor (another core component of a search engine) to function efficiently. When you type a query, the search engine:
- Processes your query words similarly (tokenization, normalization, stemming).
- Looks up each processed query term in the vast index.
- Instantly retrieves the lists of documents associated with each term.
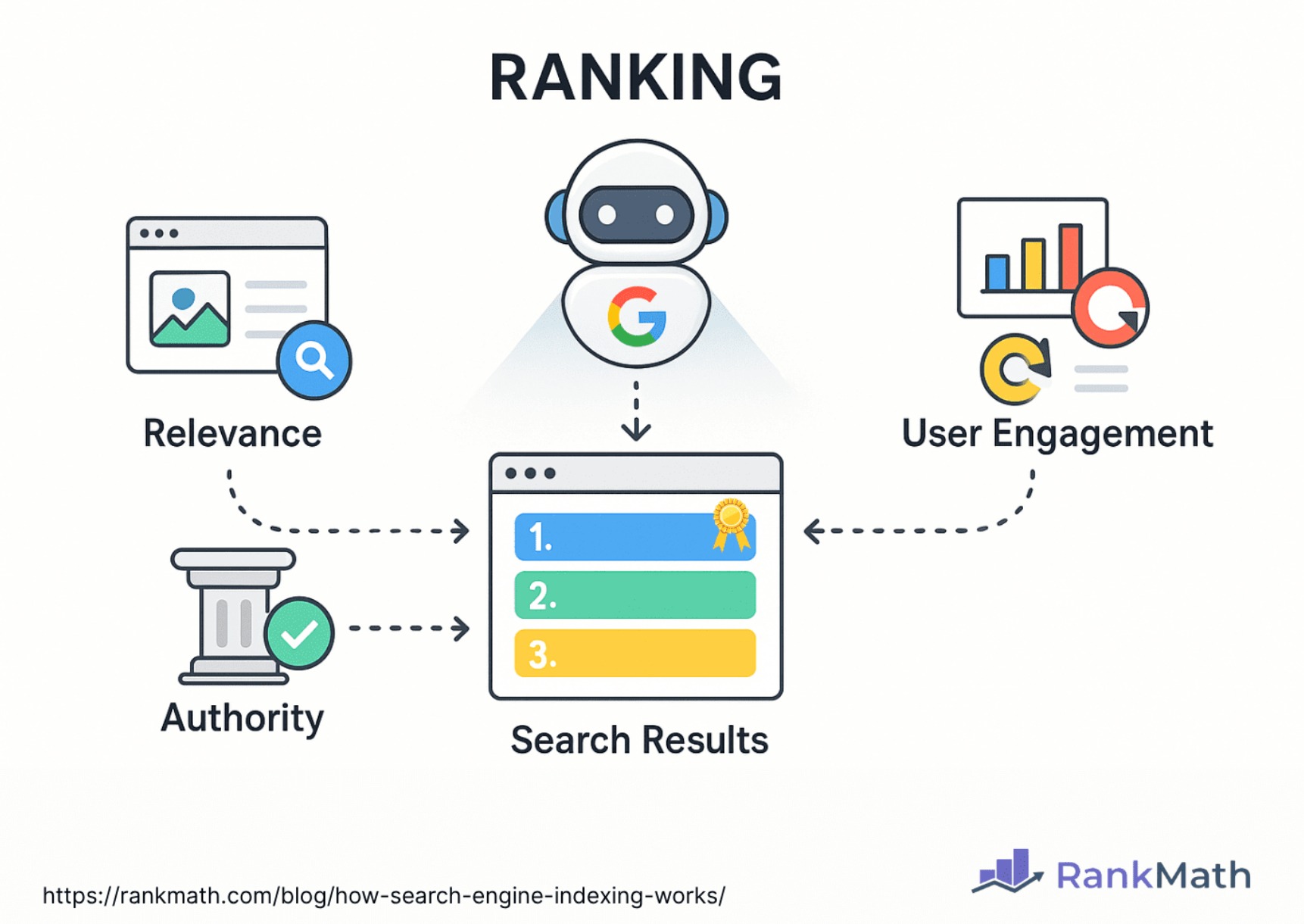
- Uses complex ranking algorithms to evaluate the relevance and importance of documents containing those terms (leveraging the stored frequency, position, prominence, etc.).
Without the indexer pre-processing and organizing the web's content, performing comprehensive searches across billions of pages in fractions of a second would be computationally impossible.